
Open LLM Leaderboard

概述
Open LLM Leaderboard 是由 HuggingFace 推出的全球权威开源大型语言模型(LLMs)评估与排名平台,旨在系统化衡量和展示开源大模型在多项核心任务中的性能表现。该平台基于 Eleuther AI 开发的 Language Model Evaluation Harness(LME)框架构建,覆盖阅读理解、逻辑推理、数学计算、事实问答等六大核心评测维度,为开发者、研究人员及企业提供了一个透明、可复现的模型对比工具。截至2025年,该榜单已收录超过200个开源大模型,成为全球机器学习社区的重要参考资源。
---
技术架构与评估体系
1. 核心框架:
平台依托 Eleuther AI 的 LME 评估框架,通过标准化测试集和自动化评估流程,确保结果的客观性。所有模型需在统一环境下运行,避免硬件或部署差异对结果的影响。
2. 评测维度:
- 基础能力:包括常识推理(Common Sense)、事实准确性(Factuality)等。
- 专业技能:如数学计算(Math)、代码生成(Code)、多语言支持(Multilingual)。
- 高级任务:逻辑推理(Logic)、阅读理解(Reading Comprehension)及对话一致性(Consistency)。
3. 动态更新机制:
榜单数据实时同步至 HuggingFace 官网及镜像站点,支持开发者自主提交新模型或更新版本参与评测。平台每月发布详细报告,分析模型性能变化趋势。
---
发展历程与里程碑
- 2023年:
HuggingFace 正式推出 Open LLM Leaderboard 1.0,初期覆盖30余个开源模型,聚焦英文场景评测。
- 2024年:
发布 v2版本,新增多语言支持与更复杂的推理任务(如长文本理解),并引入动态权重评分系统,综合考量模型速度与准确性。
- 关键事件:
2024年5月,中国开源模型 “通义千问” 在综合排行榜中首次登顶,展示出在多语言和逻辑推理任务中的领先优势(参考文档3)。
---
应用场景与市场影响
1. 开发者决策支持:
企业与研究人员通过榜单快速筛选适合特定任务的开源模型,例如电商可优先选择在阅读理解任务中表现优异的模型用于客服系统。
2. 推动开源生态:
榜单激励开发者优化模型性能,促进开源社区贡献高质量代码与数据集。例如,2024年榜单推动了多模态评测任务的标准化进程。
3. 行业影响力:
据 HuggingFace 官方统计,平台每月吸引超30万独立访问者,成为学术会议(如 NeurIPS)和行业峰会的参考基准(文档4)。
---
技术挑战与未来方向
- 当前挑战:
- 评测覆盖不足:对小语种(如东南亚语言)及垂直领域(医疗、法律)的支持仍需扩展。
- 计算资源限制:部分复杂任务(如长文本生成)因算力成本较高尚未纳入核心评测指标。
- 未来规划:
- 引入 动态任务库,支持用户自定义评测场景。
- 探索与行业合作,增加医疗、金融等领域的专项评测。
---
参考来源与版本说明
- 官方入口:
- 技术白皮书:
- 数据更新频率:每日自动同步,重大版本迭代每季度发布(如v2.1于2025年Q1上线)。
(注:本文数据截至2025年4月,部分细节引用自HuggingFace官方文档及行业媒体报道。)
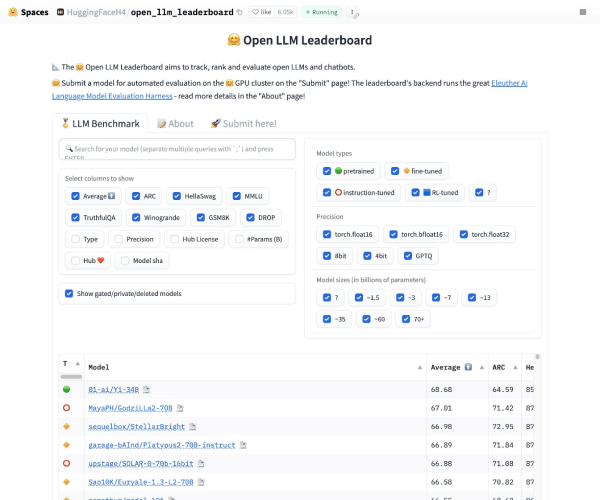
应用截图
2. 本站积分货币获取途径以及用途的解读,想在本站混的好,请务必认真阅读!
3. 本站强烈打击盗版/破解等有损他人权益和违法作为,请各位会员支持正版!
4. AI模型评测 > Open LLM Leaderboard

