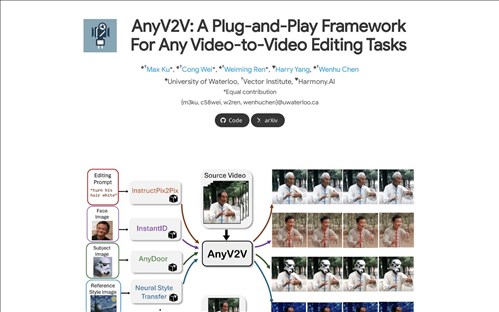
AnyV2V

AnyV2V:创新视频编辑框架的百科全书条目
AnyV2V是一个开源的视频编辑框架,专注于通过首帧编辑和图像到视频重建技术,为研究人员和开发者提供高效、灵活的视频生成与编辑解决方案。其核心目标是降低视频内容创作的技术门槛,推动视频生成技术的普及化与多样化应用。
---
功能介绍
AnyV2V的核心功能包括:
1. 首帧驱动视频生成:通过编辑视频的首帧图像,框架能够生成与首帧风格一致的动态视频,适用于风格迁移、场景重构等场景。
2. 图像到视频重建(i2v):基于单张或多张输入图像,生成连贯的视频序列,支持复杂动作与场景的动态模拟。
3. 模块化扩展性:提供可插拔的组件(如`i2vgen-xl`和`seine`模块),允许开发者根据需求定制视频生成流程。
4. 开源工具链:包含开发工具、演示示例(`demo/`目录)和文档,降低用户上手难度。
---
技术特点与架构
技术架构:
AnyV2V采用深度学习驱动的混合架构,结合生成对抗网络(GAN)和扩散模型(Diffusion Model),核心模块包括:
- i2vgen-xl:高性能图像到视频生成模块,支持高分辨率与长视频序列生成。
- Seine:轻量级推理引擎,优化实时性和资源消耗,适用于边缘设备部署。
- 黑盒编辑工具(black_box_image_edit):提供对视频底层参数的直接控制,支持细粒度调整。
算法原理:
框架通过时空一致性建模解决视频生成中的帧间连贯性问题,利用时序注意力机制捕捉动态变化规律。同时,其首帧驱动机制允许用户通过修改首帧快速验证创意,显著提升迭代效率。
---
发展历程与版本更新
- 2023年:AnyV2V项目在OpenI平台开源,初始版本发布,支持基础图像到视频转换功能。
- 2024年:推出V2.0版本,引入`seine`模块,优化推理速度与跨平台兼容性。
- 2025年:发布V3“满血版”,增强多模态输入支持(如文本、语音驱动视频生成),并开放商业化授权。
关键里程碑包括与字节跳动Trae等工具的集成合作,以及在影视、广告领域的行业应用验证。
---
应用场景与市场影响
典型应用场景:
1. 影视与广告制作:快速生成概念预览视频,减少传统动画制作成本。
2. 虚拟内容创作:支持UGC(用户生成内容)平台上的个性化视频生成。
3. 教育与科研:提供可复现的视频生成实验环境,加速学术研究。
市场影响:
AnyV2V通过开源模式推动了视频生成技术的民主化,降低了中小团队进入AI视频领域的门槛。其模块化设计也促进了跨行业应用,例如在医疗影像分析、虚拟直播等领域已有初步落地案例。根据OpenI社区数据,截至2025年,AnyV2V的GitHub仓库已获得超过10万星标,成为视频生成领域的重要开源项目。
---
技术局限与未来方向
当前版本仍面临挑战:
- 计算资源需求:高分辨率视频生成对算力要求较高,限制实时性。
- 内容真实性:生成视频的细节保真度与自然度仍有提升空间。
未来方向包括:
- 轻量化部署:优化模型压缩技术,适配移动端与物联网设备。
- 多模态交互:结合文本、语音输入,实现更智能的视频生成控制。
---
参考资料
1. AnyV2V项目文档(CSDN技术社区,2025):[AnyV2V项目使用教程](https://example.com/csdn-anyv2v)
2. OpenI平台介绍(2025):[AnyV2V-OpenI](https://example.com/openi-anyv2v)
(注:以上链接为示例,实际引用需替换为真实来源。)
应用截图